Publications
I would be delighted to discuss my research works with you.
2026
- ACL
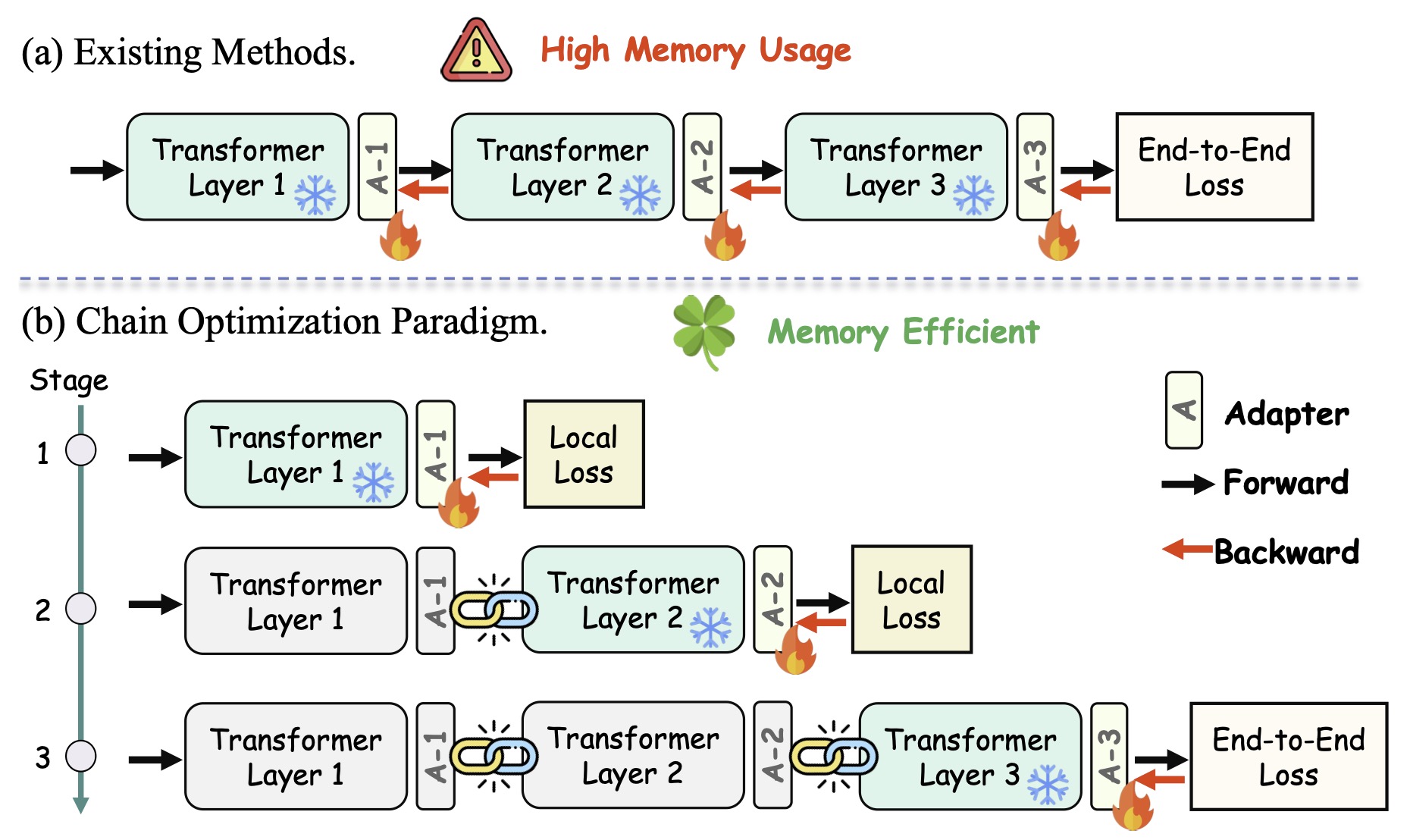 Beyond End-to-End: Dynamic Chain Optimization for Private LLM Adaptation on the EdgeYebo Wu*, Jingguang Li*, Chunlin Tian, and 3 more authorsIn ACL, 2026
Beyond End-to-End: Dynamic Chain Optimization for Private LLM Adaptation on the EdgeYebo Wu*, Jingguang Li*, Chunlin Tian, and 3 more authorsIn ACL, 2026Federated fine-tuning enables privacy-preserving LLM adaptation but faces a critical bottleneck: the disparity between LLMs’ high memory demands and edge devices’ limited capacity. To break the memory barrier, we propose Chain Federated Fine-Tuning (ChainFed), an innovative paradigm that forgoes end-to-end updates in favor of a sequential, layer-by-layer manner. It first trains the initial adapter to convergence, freezes its weights, and then proceeds to the next. This iterative train-and-freeze process forms an optimization chain, gradually enhancing the model’s task-specific proficiency. ChainFed further integrates three core techniques: 1) Dynamic Layer Co-Tuning to bridge semantic gaps between sequentially tuned layers and facilitate information flow; 2) Globally Perceptive Optimization to endow each adapter with foresight beyond its local objective; 3) Function-Oriented Adaptive Tuning to automatically identify the optimal fine-tuning starting point. Extensive experiments on multiple benchmarks demonstrate the superiority of ChainFed over existing methods, boosting average accuracy by up to 46.46%.
- TMLR
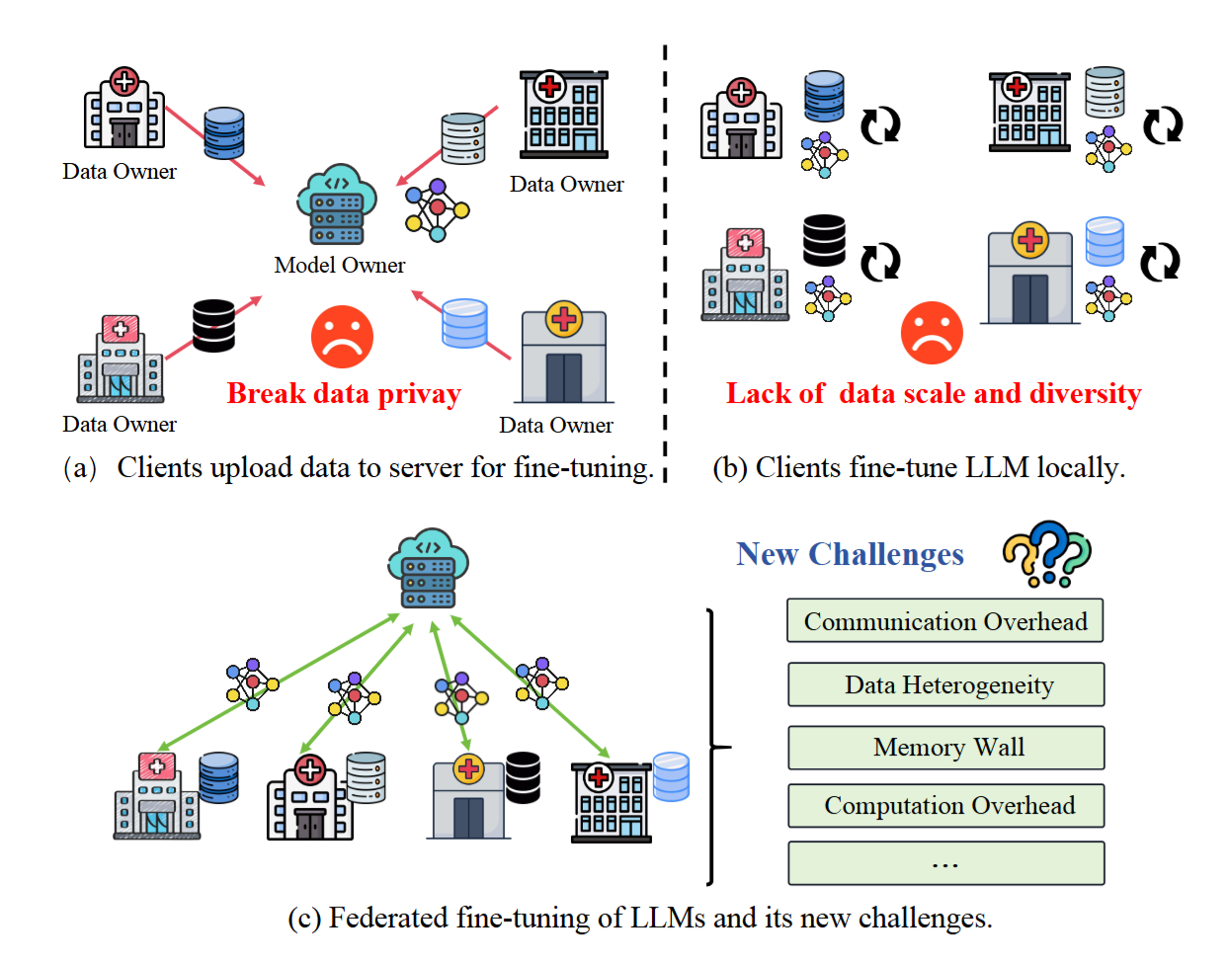 A Survey on Federated Fine-Tuning of Large Language ModelsYebo Wu, Chunlin Tian, Jingguang Li, and 7 more authorsIn TMLR, 2026
A Survey on Federated Fine-Tuning of Large Language ModelsYebo Wu, Chunlin Tian, Jingguang Li, and 7 more authorsIn TMLR, 2026Large Language Models (LLMs) have demonstrated impressive success across various tasks. Integrating LLMs with Federated Learning (FL), a paradigm known as FedLLM, offers a promising avenue for collaborative model adaptation while preserving data privacy. This survey provides a systematic and comprehensive review of FedLLM. We begin by tracing the historical development of both LLMs and FL, summarizing relevant prior research to set the context. Subsequently, we delve into an in-depth analysis of the fundamental challenges inherent in deploying FedLLM. Addressing these challenges often requires efficient adaptation strategies; therefore, we conduct an extensive examination of existing Parameter-Efficient Fine-tuning (PEFT) methods and explore their applicability within the FL framework. To rigorously evaluate the performance of FedLLM, we undertake a thorough review of existing fine-tuning datasets and evaluation benchmarks. Furthermore, we discuss FedLLM’s diverse real-world applications across multiple domains. Finally, we identify critical open challenges and outline promising research directions to foster future advancements in FedLLM. This survey aims to serve as a foundational resource for researchers and practitioners, offering valuable insights into the rapidly evolving landscape of federated fine-tuning for LLMs. It also establishes a roadmap for future innovations in privacy-preserving AI.
- ICLR
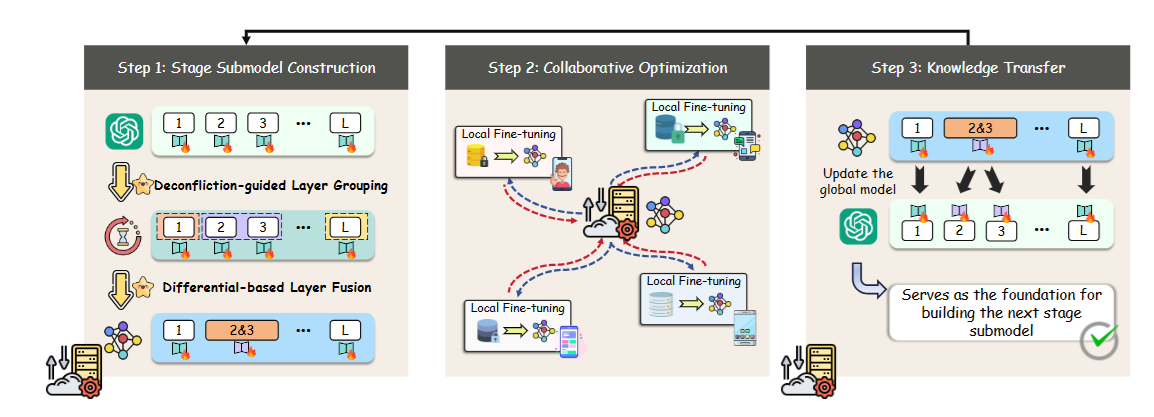 Learning Like Humans: Resource-Efficient Federated Fine-Tuning through Cognitive Developmental StagesYebo Wu*, Jingguang Li*, Zhijiang Guo, and 1 more authorIn ICLR, 2026
Learning Like Humans: Resource-Efficient Federated Fine-Tuning through Cognitive Developmental StagesYebo Wu*, Jingguang Li*, Zhijiang Guo, and 1 more authorIn ICLR, 2026Federated fine-tuning enables Large Language Models (LLMs) to adapt to downstream tasks while preserving data privacy, but its resource-intensive nature limits deployment on edge devices. In this paper, we introduce Developmental Federated Tuning (DevFT), a resource-efficient approach inspired by cognitive development that progressively builds a powerful LLM from a compact foundation. DevFT decomposes the fine-tuning process into developmental stages, each optimizing submodels with increasing parameter capacity. Knowledge from earlier stages transfers to subsequent submodels, providing optimized initialization parameters that prevent convergence to local minima and accelerate training. This paradigm mirrors human learning, gradually constructing comprehensive knowledge structure while refining existing skills. To efficiently build stage-specific submodels, DevFT introduces deconfliction-guided layer grouping and differential-based layer fusion to distill essential information and construct representative layers. Evaluations across multiple benchmarks demonstrate that DevFT significantly outperforms state-of-the-art methods, achieving up to 4.59x faster convergence, 10.67x reduction in communication overhead, and 9.07% average performance improvement, while maintaining compatibility with existing approaches.
2025
- arXiv
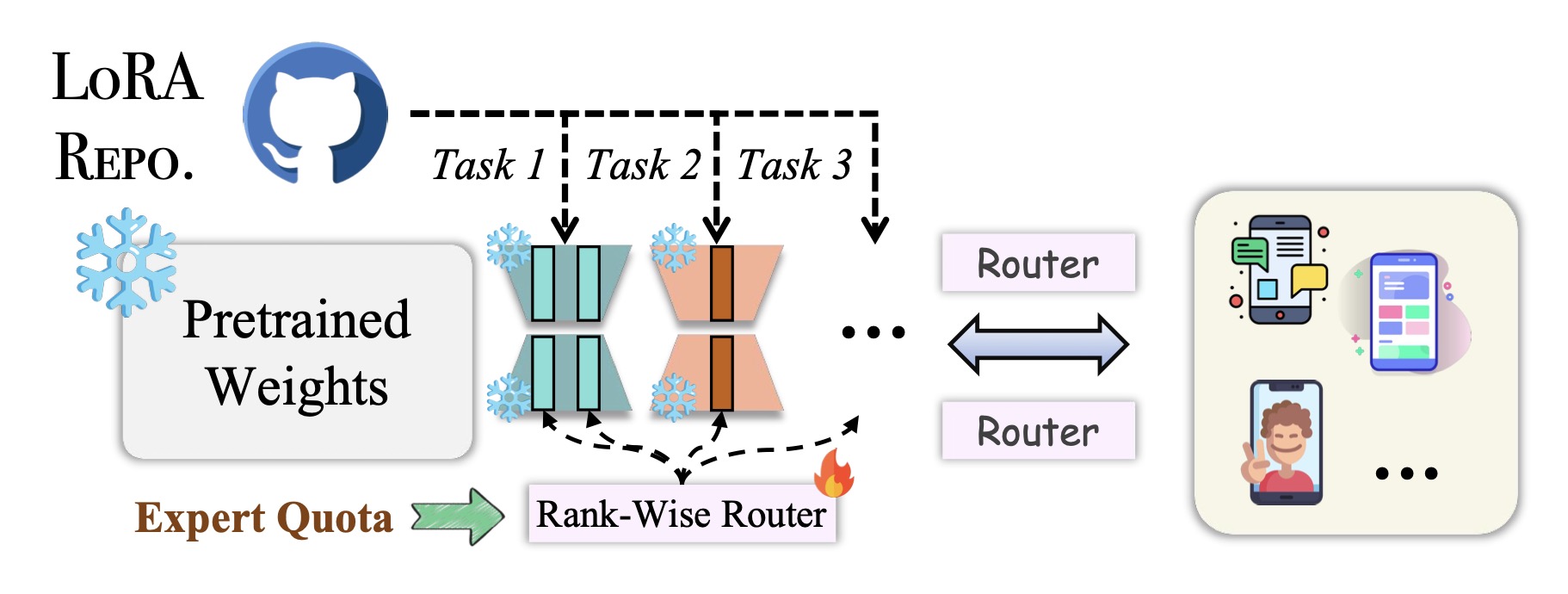 Elastic Mixture of Rank-Wise Experts for Knowledge Reuse in Federated Fine-TuningYebo Wu*, Jingguang Li*, Zhijiang Guo, and 1 more authorIn arXiv, 2025
Elastic Mixture of Rank-Wise Experts for Knowledge Reuse in Federated Fine-TuningYebo Wu*, Jingguang Li*, Zhijiang Guo, and 1 more authorIn arXiv, 2025Federated fine-tuning offers a promising solution for adapting Large Language Models (LLMs) to downstream tasks while safeguarding data privacy. However, its high computational and communication demands hinder its deployment on resource-constrained devices. In this paper, we propose SmartFed, a resource-efficient federated fine-tuning framework. SmartFed intelligently reuses knowledge embedded in existing LoRA modules, eliminating the need for expensive training from scratch when adapting LLMs to new tasks. To effectively exploit this knowledge and ensure scalability, we introduce the Mixture of Rank-Wise Experts (MoRE). MoRE decomposes LoRA modules into fine-grained rank-level experts. These experts are selectively activated and combined based on input semantics and resource budgets. Moreover, to optimize resource utilization, we present the Elastic Expert Quota Allocation (EEQA). EEQA adaptively allocates expert capacity across parameter matrices based on their contribution to model performance, focusing computing resources on the critical experts. Extensive evaluations across multiple benchmarks demonstrate that SmartFed significantly outperforms existing methods in model performance and training efficiency.
- arXiv
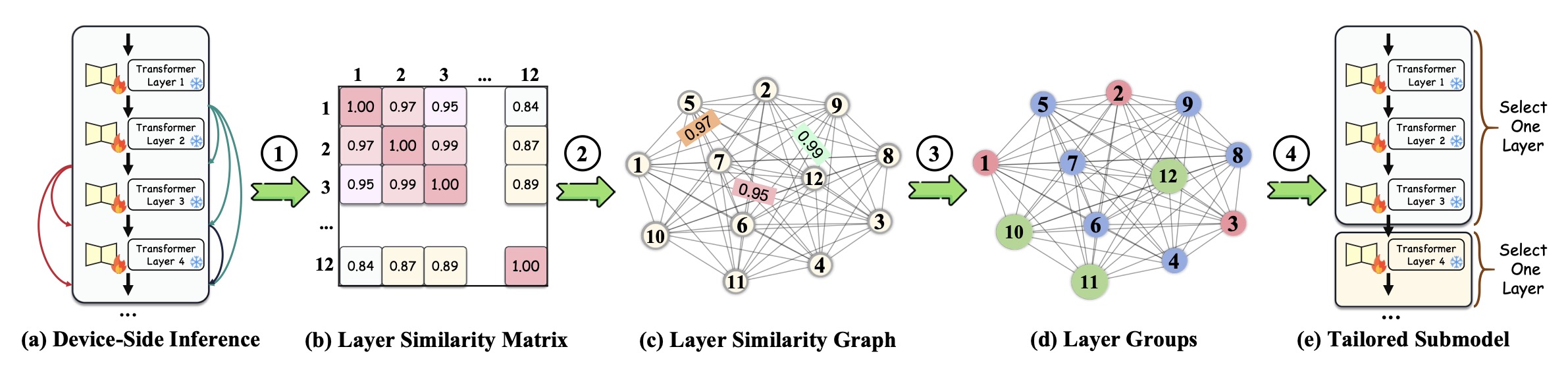 Memory-Efficient Federated Fine-Tuning of Large Language Models via Layer PruningYebo Wu*, Jingguang Li*, Chunlin Tian, and 2 more authorsIn arXiv, 2025
Memory-Efficient Federated Fine-Tuning of Large Language Models via Layer PruningYebo Wu*, Jingguang Li*, Chunlin Tian, and 2 more authorsIn arXiv, 2025Federated fine-tuning enables privacy-preserving Large Language Model (LLM) adaptation, but its high memory cost limits participation from resource-constrained devices. We propose FedPruner, an innovative federated fine-tuning paradigm that tackles this via intelligent layer pruning. FedPruner flexibly prunes the global model, creating personalized submodels based on device memory constraints. It employs a macro-micro synergistic pruning framework: a macro-level functionality-driven layer orchestration mechanism groups layers, while a micro-level importance-aware layer selection strategy prunes within groups to build device-specific submodels. We further introduce a fine-grained variant that independently prunes Multi-Head Attention and Feed-Forward Network components to precisely preserve critical architectural elements. Extensive experimental results demonstrate that FedPruner significantly outperforms state-of-the-art approaches, achieving up to a 1.98% improvement in average model accuracy while reducing peak memory usage by 75%.
2024
- arXiv
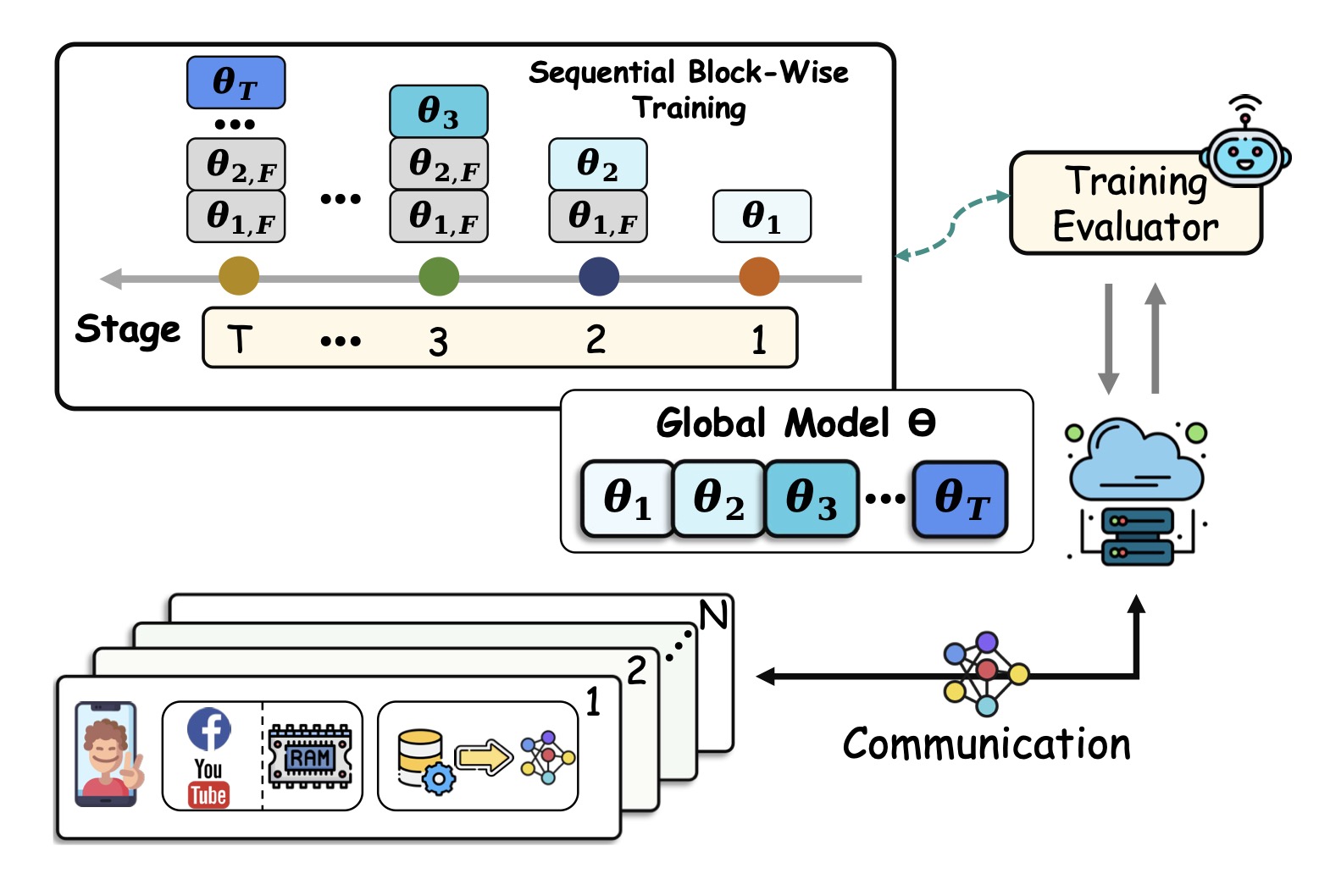 Bridging Memory Gaps: Scaling Federated Learning for Heterogeneous ClientsYebo Wu, Jingguang Li, Chunlin Tian, and 3 more authorsIn arXiv, 2024
Bridging Memory Gaps: Scaling Federated Learning for Heterogeneous ClientsYebo Wu, Jingguang Li, Chunlin Tian, and 3 more authorsIn arXiv, 2024Federated Learning (FL) enables multiple clients to collaboratively train a shared model while preserving data privacy. However, the high memory demand during model training severely limits the deployment of FL on resource-constrained clients. To this end, we propose ScaleFL, a scalable and inclusive FL framework designed to overcome memory limitations through sequential block-wise training. The core idea of ScaleFL is to partition the global model into blocks and train them sequentially, thereby reducing training memory requirements. To mitigate information loss during block-wise training, ScaleFL introduces a Curriculum Mentor that crafts curriculum-aware training objectives for each block to steer their learning process. Moreover, ScaleFL incorporates a Training Harmonizer that designs a parameter co-adaptation training scheme to coordinate block updates, effectively breaking inter-block information isolation. Extensive experiments on both simulation and hardware testbeds demonstrate that ScaleFL significantly improves model performance by up to 84.2%, reduces peak memory usage by up to 50.4%, and accelerates training by up to 1.9x.